

Le scrum efficace : melba fait des sprints et les réussit
Comment melba a réussi à comprendre le scrum pour rendre le développement logiciel efficace




Melba a rencontré de nombreuses difficultés avant de parvenir à mettre en place un processus de développement logiciel efficace.
On entend par efficace :
- Travailler sur les bons sujets
- Rendre prédictible le résultat à obtenir au bout d’une période donnée
- Avoir une capacité à faire (CAF) convenable
- Mettre en production régulièrement
- Ne pas avoir de régression lors des mises en production
- Itérer en augmentant notre CAF
- Satisfaire l’équipe de développement et toute l’entreprise
Prérequis
Avant d’essayer d’organiser efficacement le travail d’une équipe de développement, il convient de déterminer un périmètre de travail cohérent. Nous y sommes parvenus via la mise en place d’un process produit de qualité.
Cela suppose que nous soyons parvenu à déterminer précisément les prochaines priorités fonctionnelles :
- ces priorités découlent de l’expression du besoin émise par les utilisateurs et d’initiatives stratégiques qui servent notre vision
- elles sont précises – le travail d’UX et d’UI a levé les doutes relatifs au fait que la solution réponde au besoin
Il faut aussi que l’équipe partage la philosophie scrum et qu’une première personne ait une expérience positive de son application. C’est le cas chez nous, un de nos* lead developers* l’a ardemment pratiquée.
On a par ailleurs pu se rendre compte de nos erreurs de jeunesse à la lecture de *Scrum en Action* de Guillaume Bodet. Le livre décrit une bascule que l’on a expérimentée, du travail en cycle en V à l’application de scrum. Un contrat avec un grand groupe avait donné lieu à la rédaction d’un cahier des charges volumineux. Le besoin n’était clair pour personne, évoluait fréquemment et les exigences de notre partenaire et notre envie de nous y conformer nous amenait à sacrifier la qualité : nous étions tombés dans un cercle vicieux où l’urgence nous poussait à bâcler et à mettre en production tous les 3 mois pour se rendre compte de nombreuses régressions et d’une inadéquation avec le besoin des utilisateurs.
Scrum est un outil de communication. Scrum permet aux équipes de se synchroniser efficacement, de travailler sur des choses qui comptent et d’en tirer des bénéfices rapidement. Être anti-scrum c’est ne pas vouloir communiquer efficacement.
Il y a plusieurs cas d’allergie au scrum :
- une première expérience malheureuse qui assimile la méthode à une religion rythmée par des cérémonies inutiles. A quoi bon faire un stand-up et répéter pour la 5ème fois de la semaine le sujet qui nous occupe depuis le début ? Il faut réaliser que le problème est de travailler sur le même sujet depuis 5 jours.
- une aversion aux process qui peut découler de la peur d’être fliqué : “laisse moi faire”. Ca ne s’excuse pas, les process permettent de *scaler *en équipe, dans tous les départements.
Aujourd’hui melba met en production de très petites tâches 2 à 5 fois par jour sans régression. Nos utilisateurs nous font tous les jours des retours que nous sommes en capacité de traiter rapidement.
La préparation des sprints
Nous avons choisi de travailler sur des sprints courts : 1 semaine.
Cela augmente le overhead mais diminue le travail de préparation et permet d’être plus agile. On pourrait adapter le curseur et choisir de diminuer l’overhead en augmentant le risque lié à la fixation d’un périmètre fonctionnel plus important. Risque :
- que les tickets manquent de préparation
- que le besoin change
- que des éléments extérieurs dérangent le sprint (bug à résoudre en urgence…)
Car un sprint c’est bien cela : figer la todo de l’équipe de développement pour lui permettre de travailler dans des conditions confortables, sans interruption et sans changement de direction. L’équipe de développement sait quoi faire sur la semaine qui suit et personne ne va la déranger.
Le sprint est constitué de user stories (US).
Avant de rentrer dans le détail, voici ci-dessous une carte Trello représentative d’une US. Son contenu est décrit dans les paragraphes suivants.
Exemple d’une US complète :
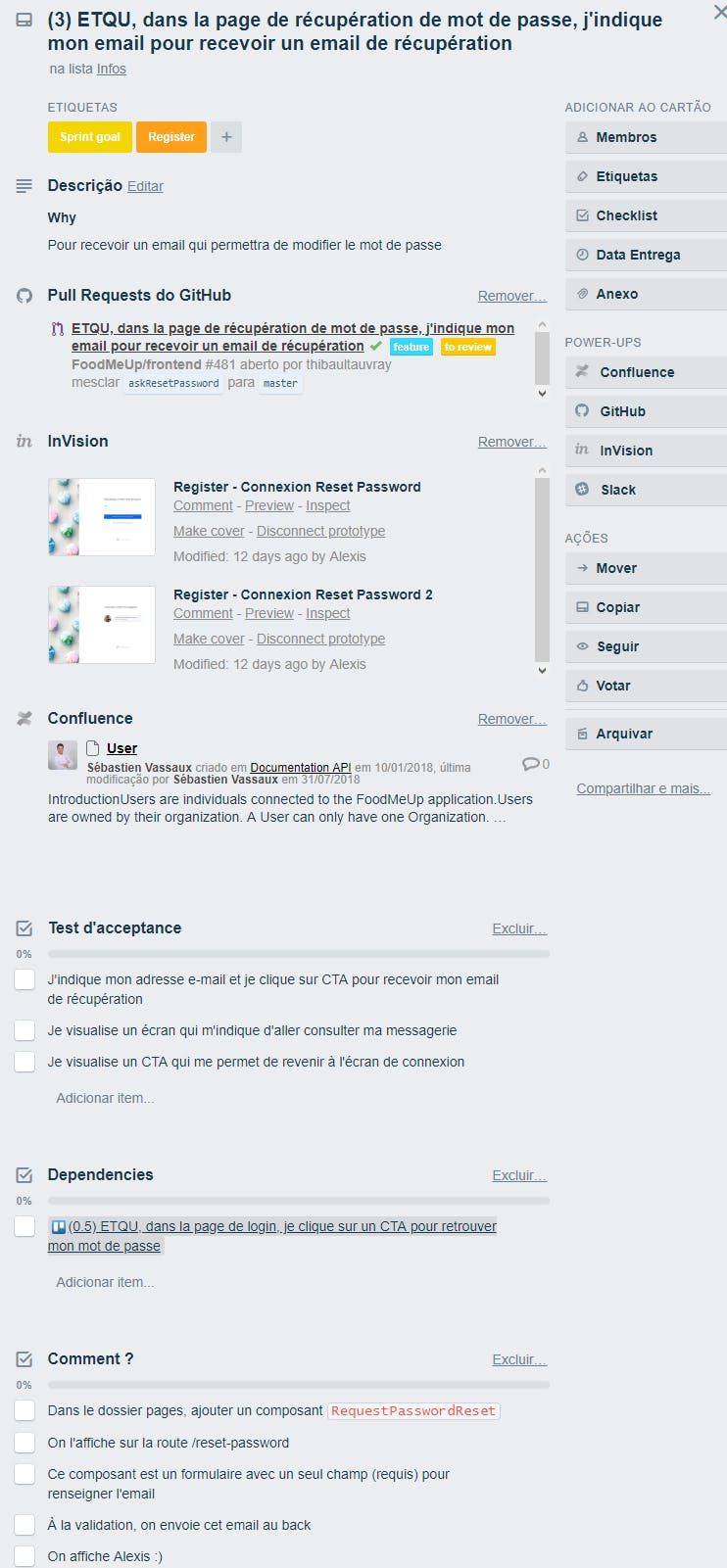
Une user story explicite et documentée
Une US prend le format suivant :
En tant que <persona>, lorsque je me trouve dans <contexte>, je veux <action / résultat >
On définit également le Why : pourquoi est-ce important, quel est le besoin de l’utilisateur.
Enfin, on ajoute un lien vers une maquette et les autres ressources éventuellement nécessaires (police, picto, image, etc.) afin de limiter le temps de recherche de l’équipe de développement.
On lie l’US à notre wiki qui récapitule tous les tests d’acceptance ainsi qu’à notre documentation d’API statique. Cette documentation d’API statique, rédigée sur le modèle de celle de Stripe, est au développement backend ce que les maquettes sont au développement frontend.
Chaque US peut être mise en production. Si elle fait partie d’un parcours dont le set minimal n’est pas encore prêt à partager avec des utilisateurs, elle est toutefois mise en production et cachée.
Note : on fait parfois la différence entre user story et job story. Melba fait plutôt des job* stories qui comportent le contexte tandis que les user stories ne* le comprennent traditionnellement pas.
Les tests d’acceptance
Les tests d’acceptance comportent les éléments de logique métier que la fonctionnalité doit satisfaire. C’est intéressant de découper les US en éléments de petite envergure afin de ne pas imposer une logique trop complexe et ainsi identifier plus facilement des edge cases.
Les tests d’acceptance permettent de se projeter facilement sur le résultat : le développeur qui finit son travail doit cocher les différents éléments ce qui indique qu’il a vérifié que le résultat attendu est obtenu. Si des comportements attendus ne sont pas listés dans ces tests d’acceptance, le PO doit créer un nouveau ticket.
Le backlog refinement
Le backlog refinement est l’occasion pour le PO, l’UX et des membres de l’équipe de développement de parcourir l’ensemble des tickets pressentis pour le prochain sprint (voire un peu plus) afin d’éliminer des incompréhensions, imprécisions, risques, etc..
Des ateliers et des présentations des travaux de conception en amont du backlog refinement permettent de sensibiliser l’équipe technique aux enjeux fonctionnels, mais lors de la découpe on entre dans un niveau de raffinement qui rend cet échange nécessaire. La connaissance métier de l’UX et du PO est partagée et l’équipe technique aide à faire des arbitrages qui vont dans le sens d’un meilleur ROI.
La découpe technique
Un deuxième échange est prévu en amont du lancement du sprint pour permettre à l’équipe technique de préciser la todo technique. A cette occasion, chaque tâche fonctionnelle est découpée techniquement.
L’enjeu est de supprimer tous les points de doute de sorte à ce qu’il n’y ait pas d’inconnue lors du développement. Ainsi, on va jusqu’à nommer certaines classes et méthodes et expliciter ce qui va être fait et comment, collectivement, entre développeurs. C’est l’occasion pour les seniors de transmettre aux junior leur expérience plutôt que de leur imposer en flux tendu une todo incomprise ou les laisser patauger.
Exemple d’une découpe technique précise
Si la découpe technique n’est pas possible ou est incertaine, alors on ne sera pas sûr de savoir évaluer la complexité de la tâche et on devra timeboxer le temps passé dessus pour éviter de trop se perdre. On y reviendra.
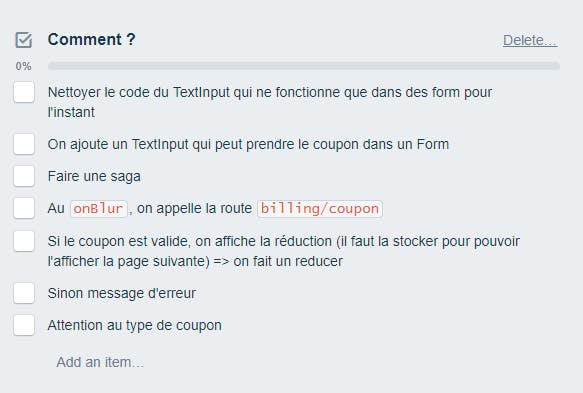
Le sprint planning
Lors du planning, l’équipe de développement accompagnée du PO passe en revue les différents tickets.
Ce planning n’est pas une souffrance comme il a pu l’être par le passé quand l’équipe découvrait des besoins incompatibles avec sa capacité à faire ou recelant encore d’énormes inconnues. La collaboration en amont a porté ses fruits.
Le planning poker
La capacité à faire est estimée en points de complexité. Cela ne correspond pas strictement à un temps de travail disponible. Toutefois on déduit de la CAF théorique le temps que prendraient les évènements non associés au développement (réunions, entretiens, etc.). A cette occasion uniquement, on fait l’amalgame entre la complexité et le temps de travail.
En particulier, on déduit de la CAF totale le temps dédié au backlog refinement, à la découpe technique et au sprint planning. Cela incite à en faire des réunions efficaces et supprime le risque lié au fait que ces réunions puissent se rallonger.
Pour estimer la complexité, nous utilisons un jeu de cartes agile et nous nous basons sur des tickets de référence. On note chaque ticket et la somme des notes des tickets à faire doit être proche de la CAF de l’équipe dont on affine la mesure sprint après sprint.
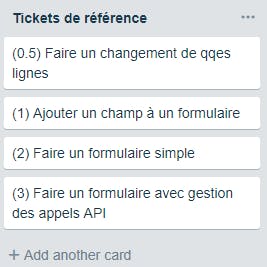
Chaque membre de l’équipe estime de manière indépendante la complexité des tâches et présentant à l’équipe une carte du jeu Agile sur laquelle figure un chiffre. S’il n’y pas de consensus sur cette estimation, les extrêmes s’expriment jusqu’à ce qu’un consensus soit trouvé.
Cela ne fonctionne que si on respecte les éléments suivants :
- l’US est claire
- l’équipe technique en a pris connaissance
- la tâche est découpée techniquement
- la complexité est faible < 5 qui équivaut si on se permet une conversion à une journée de travail
Si on ne sait pas estimer la complexité, on timebox le temps passé sur la tâche. Exemple :
Un ticket timeboxé :
A la fin d’une timebox, on a soit :
- terminé le ticket : bravo !
- résolu l’incertitude technique : on créé un nouveau ticket qui suit le même formalisme
- échoué : la timebox a permis d’éviter de passer trop de temps sur un sujet au résultat improbable. En conséquence, un junior demande de l’aide à un senior, un senior s’adresse à un collègue ou challenge le ROI du ticket et ouvre une discussion avec le PO.
Lors du planning poker, l’équipe prend les tickets du product backlog qui ont été priorisés par importance décroissante et les estime tour à tour. L’équipe arrête d’estimer les tickets du product backlog quand la somme des points de complexité des tickets insérés dans le sprint backlog dépasse la CAF moyenne de l’équipe.
L’équipe a veillé aux deux points suivants lors de la définition du périmètre du sprint.
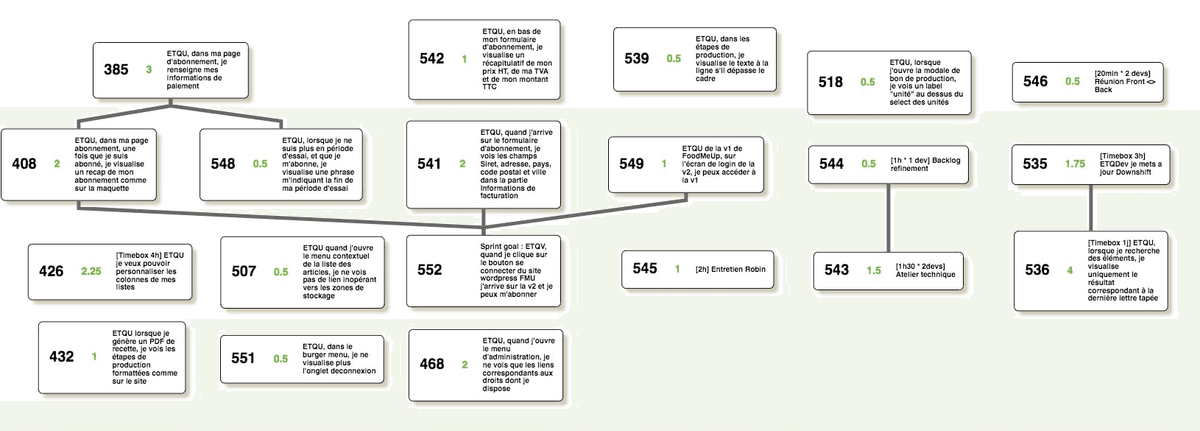
Le graph de dépendances
Un graph de dépendances des tickets est réalisé qui permet de définir dans quel ordre effectuer les tickets.
Les dépendances sont telles que l’équipe ne peut théoriquement pas être bloquée. Si une fonctionnalité bloque toutes les autres, le périmètre du sprint est modifié pour laisser à l’équipe de la marge de manœuvre sur des tâches parallèles et exploiter au mieux sa CAF.
Exemple d’un graphe de dépendances entre tickets d’un sprint :
Le sprint goal
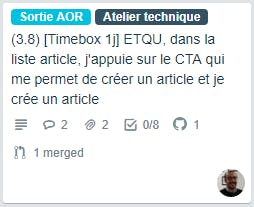
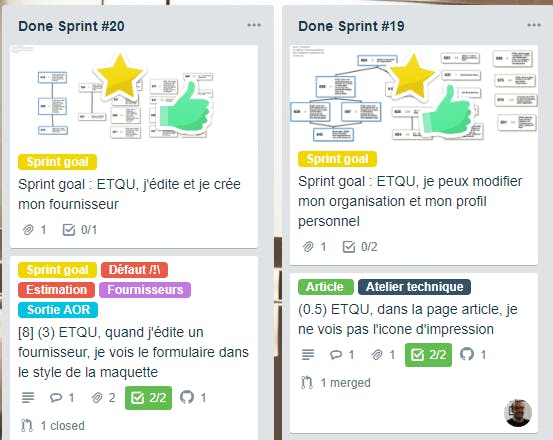
Une fois l’ensemble des tickets évalué et le périmètre du sprint figé, on défini un sprint goal.
Le sprint goal englobe plusieurs tickets et constitue la priorité de l’équipe de développement, c’est une macro-US, un epic ou encore un parcours complet. C’est la priorité du sprint global.
Il doit être suffisamment élémentaire pour que moins de 50% de la CAF de l’équipe puisse y répondre, sans quoi on prendrait le risque des inconnues et on ne le tiendrait pas.
Exemple de deux sprint goals atteints par l’équipe :
En cours de sprint
Le daily stand-up
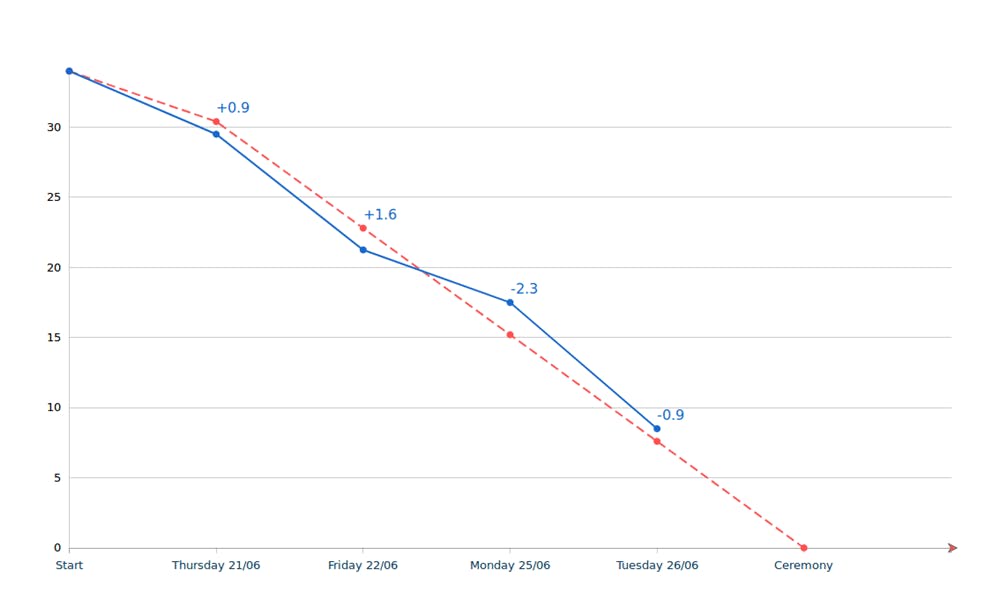
Ce qui a été fait : le burndown chart
Le matin, le PO réunit l’équipe de développement et chacun s’exprime sur ce qui a été fait. Le graphe de dépendances est utilisé et les tickets terminés sont barrés.
Le burndown chart est ré-edité et permet de savoir où l’équipe se situe par rapport à son objectif de sprint :
- Est-on en avance / en retard ?
- Est-ce qu’un problème est survenu ?
- Comment résoudre le problème ?
Ce qui reste à faire
Chaque membre de l’équipe se prononce alors sur ce qu’il va faire. Le choix est libre dans la limite de ce qu’impose le sprint backlog et le graph de dépendances, avec une priorité mise sur les tickets du sprint goal.
Chaque membre choisit également des tickets qu’il saura terminer dans la journée. On essaie de ne pas traîner un ticket d’une journée à l’autre ce qui induirait des effets indésirables :
- incapacité à tester et valider en fin de journée
- *daily stand-up *moins pertinent car travail en cours
- initiation d’une dérive amenant à ne plus favoriser la complétion des tâches
Daily email
Un récap est adressé à l’équipe entière pour tenir au courant de l’avancée. En tant que CEO, ce recap est extrêmement apprécié. C’est un reporting de qualité qui me permet de comprendre s’il y a des problèmes et de réagir en conséquence. C’est aussi un formidable outil d’aide à la décision pour le PO !
Exemple de daily email :
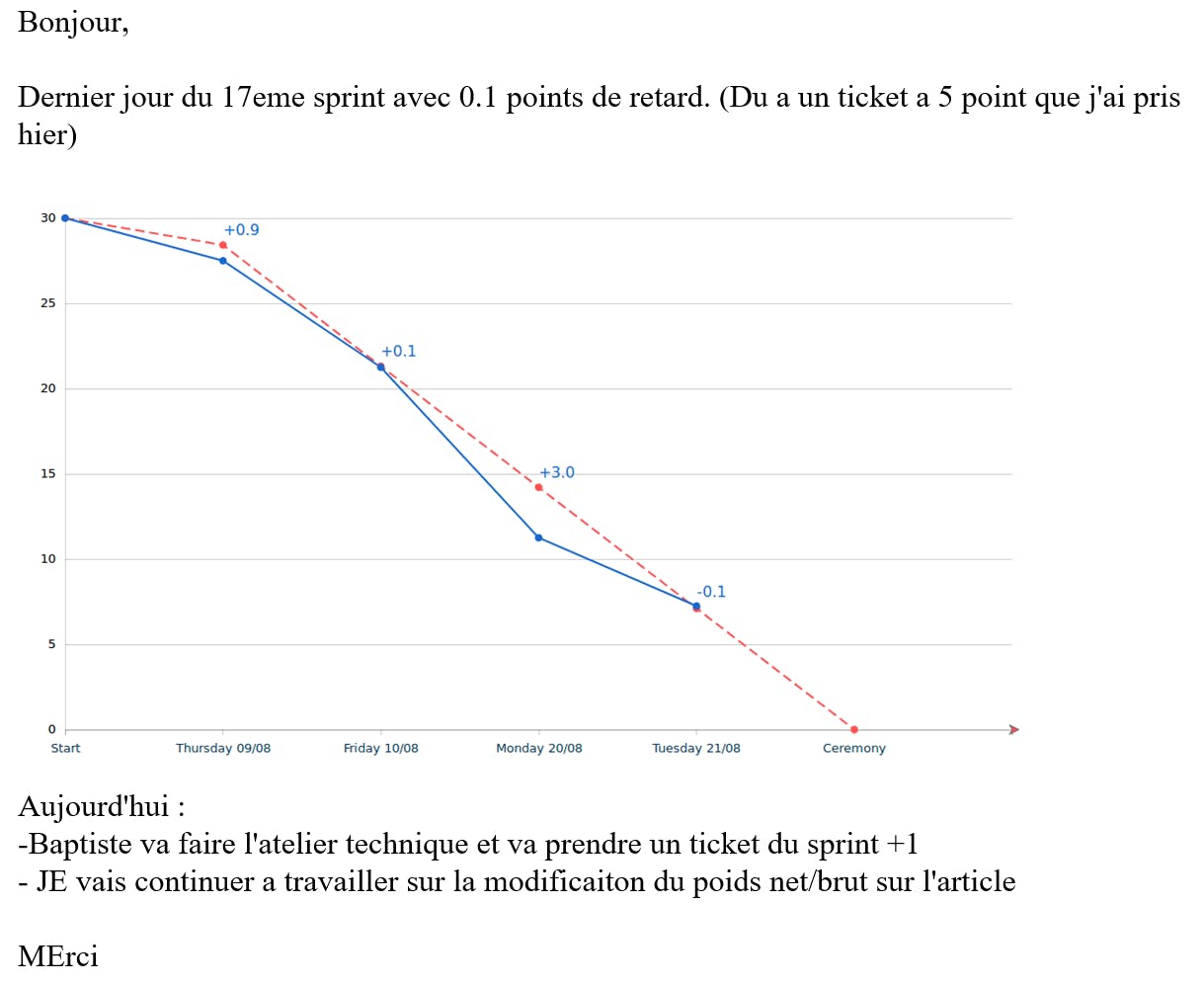
Exemple d’un autre email qui aborde une résolution de problème

La validation et la mise en production
A chaque finalisation d’un ticket par un développeur, celui ci veille à respecter :
-
les tests d’acceptance
-
La definition of done
-
les bonnes pratiques de développement en particulier les règles liées au git flow
Outre les tests d’acceptance déjà présentés, la definition of done réunit des éléments à valeur générale.
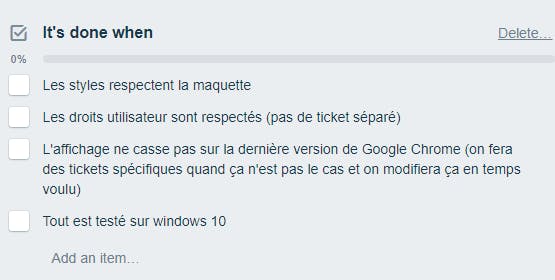
Le développeur tire une feature branch grâce à now, un outil de Zeit.co
Il effectue une PR et vérifie la conformité aux règles suivantes :
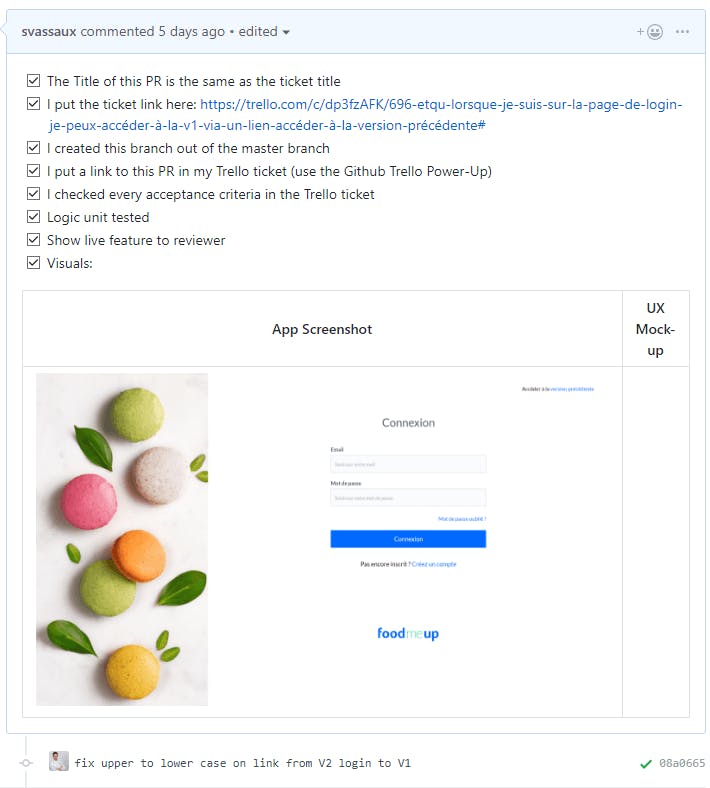
Il ne reste plus qu’à obtenir une revue positive, être à jour de master et faire passer les test sur notre outil de CI, *CircleCI *(désormais Github Actions) :
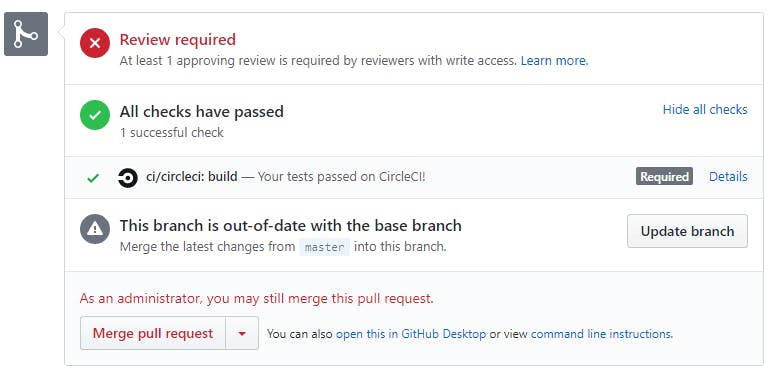
Le développeur partage alors l’adresse de la feature branch sur son ticket, une notification slack est adressée au PO qui teste. Si le test est positif, la PR est mergée et la fonctionnalité arrive directement en production 🙂
Chez melba, un push sur github lance les tests avec Cir*cleCI :
- tests unitaires sur le front avec jest, sur le back avec phpUnit
- tests fonctionnels avec cypress sur le front et behat sur le back
- tests du linter AirBnb sur le front et un linter custom sur le back
L’application est déployée sur un serveur cloud via un script ansible et le build de la SPA est effectué par webpack sur un serveur hébergé par Zeit.co.
Mettre en production très fréquemment suppose que :
- les tickets et les PR soient petits
- la lecture des PR soit prioritaire devant l’avancée d’un autre ticket
- le processus de build et de deploy soit automatisé
La lecture de *The Gold Mine* est très riche d’enseignements pour entendre l’intérêt de ce processus : toute la valeur ajoutée de l’équipe, à toute étape du cycle de développement au sens large (depuis le sourcing jusqu’aux corrections en production), est tirée au maximum vers l’utilisateur final. On garde un minimum de stock de valeur ajoutée aux différents stades de développement :
- on définit les priorités avec un calcul de ROI aligné avec nos initiatives stratégiques (cf. notre article sur le lean)
- on minimise les tickets dont les specs sont prêtes (la valeur ajoutée de notre PO réside ailleurs)
- on fait des sprint courts
- on avance sur les tâches en priorité 4
- on lit les PR en priorité 3
- on met en production en priorité 2
- on corrige les bugs en priorité 1
La rétro
Yay ! le sprint goal a été atteint et le sprint est terminé !

Il y a deux objectifs au cours d’un sprint : le sprint goal et la complétion de toutes les tâches du sprint. Le sprint goal permet de sécuriser un objectif moins ambitieux et de s’assurer qu’un gain est toutefois acquis à la fin de chaque sprint.
La démo
Nous faisons la démonstrations des nouveautés soit devant toute l’équipe soit lors de la rétro qui précède le planning (pour diminuer le overhead dû aux réunions)
La démo est utile pour se synchroniser avec les membres de l’équipe qui ne font pas partie du processus de développement du produit et participe de la satisfaction des membres de l’équipe de développement.
La résolution des problèmes
Lors de la rétro en particulier, ou à chaque daily, des problèmes sont soulevés.
Exemple :
- une US n’est pas bien rédigée
- on a engagé un sprint contenant des tickets avec des dépendances pas à jour (API pas prête)
- on a commencé un ticket long en fin de journée et le travail n’a pas pu être validé
Chacun d’entre eux fait l’objet d’une procédure de résolution des problèmes afin d’éviter qu’il ne se manifeste à nouveau.
On a emprunté à Théodo le framework de résolution des problèmes suivant avec en colonnes :
- Date et owner
- Problème rencontré et impact quantifié (1 problème max par personne par jour)
- Root cause (méthodologie des 5 Why)
- Action qui corrige la cause identifiée et l’empêche de se reproduire
- Date d’action (le jour même idéalement)
- Résultat attendu
- Date de check prévu
- Résultat observé
- Statut (problème identifié, action proposée au moment ou le problème est rencontré, action challengée par l’équipe au daily suivant, problème résolu)

Conclusion
Pendant 2 ans, melba s’est essayé au scrum sans grand succès. Nous ne respections pas suffisamment son esprit et nous n’avions pas de compétence préalable dans le domaine.
On dénigre d’ailleurs souvent cette méthodologie :
- trop rigide
- stand-up inutiles
- pas de sensibilité à la résolution de la dette technique
- travail atomique inadapté aux travaux d’architecture
- flicage
- …
Pour avoir testé du scrum qui ne marche pas puis du scrum qui marche, je pense que ces remarques sont évidentes quand on manque d’expérience mais qu’elle ne sont pas justes dans l’absolu :
- la supposée rigidité devient confort dès que le processus tourne tout seul. Quelle satisfaction que de pouvoir savoir à l’avance ce qui va être fait et de constater semaine après semaine que les objectifs sont atteints ! De plus on peut s’autoriser exceptionnellement des entrées-sorties de tickets dans la mesure où elles ne changent substantiellement le sprint.
- le stand-up est effectivement inutile si on travaille une semaine sur le même ticket et qu’on n’est pas aidé par le burndown chart et le graph de dépendances. Avec ces outils, on est succinct et on passe à l’action. On raye le ticket terminé et on ne parle des problèmes que s’ils existent.
- la dette technique peut être incluse dans les sprints. On le fait régulièrement chez melba. L’absence de sensibilité à la dette technique fait courir un risque pour l’entreprise, ça devient un sujet business également.
- l’équipe de développement a la responsabilité de bien architecturer les applicatifs et des tâches du sprint peuvent être dédiées au travaux d’architecture. Ces tâches peuvent également être timeboxées ; en fin de timebox, on en rend compte au reste de l’équipe qui décide d’y attribuer plus de temps en fonction de la levée de l’incertitude. Il peut y avoir plus de temps attribué à de la R&D et dans ce cas la CAF dédiée peut être enlevée du sprint comme c’est le cas pour tout ce qui prend du temps (réunions, entretiens, etc.)
- la méthodologie scrum permet de connaître en permanence l’avancée de l’équipe de développement notamment en garantissant une communication de grande qualité. Vaut-il mieux un système opaque qui diminue la confiance ou une transparence totale qui engendre de nombreux petits succès ?
Scrum : une expérience très positive chez melba !